5.1. Forward Recomputation Backpropagation¶
5.1.1. 简介¶
使用更大的模型和更大的batch size 可以带来更好的效果,但用户需要考虑是随之而来的显存瓶颈问题。Paddle Fleet 提供以下两种策略来解决大模型(大batch size)训练中可能遇到的显存瓶颈问题:
5.1.1.1. Forward Recomputation Backpropagation(FRB)¶
该策略通过清除正向计算过程中的中间计算结果,来降低训练过程中使用的存储空间,从而确保硬件有足够的内存做更大batch Size 的训练。
5.1.1.2. Recompute-Offload¶
基于Recompute 策略,将显存中checkpoint 卸载到Host 内存中,进一步节省显存空间支持更大batch Size的训练。
5.1.2. 原理¶
5.1.2.1. Recomputation¶
我们知道,深度学习网络的一次训练迭代包含三个步骤:
前向计算: 运行前向算子(Operator) 来计算中间隐层(Variable) 的值 。
反向计算: 运行反向算子来计算参数(Parameter)的梯度。
优化: 应用优化算法以更新参数值 。
在前向计算过程中,前向算子会计算出大量的中间结果,由于这些中间结果是训练数据和算子计算得到的,所以训练数据的batch bize 越大,中间结果占用的内存也就越大。飞桨核心框架会使用 Variable来存储这些隐层的中间结果。当模型层数加深时,其中间结果的数量可达数千甚至数万, 占据大量的内存。飞桨核心框架的显存回收机制会及时清除无用的中间结果以节省显存, 但是有些中间结果是反向计算过程中算子的输入,这些中间结果必须存储在内存中,直到相应的反向算子计算完毕。
对于大小固定的内存来说,如果用户希望使用大batch bize 的数据进行训练,则将导致单个中间结果占用内存增大,那么就需要减少中间结果的存储数量,FRB就是基于这种思想设计的。
FRB是将深度学习网络切分为k个部分(segments)。对每个segment 而言:前向计算时,除了小部分必须存储在内存中的Variable 外,其他中间结果都将被删除;在反向计算中,首先重新计算一遍前向算子,以获得中间结果,再运行反向算子。简而言之,FRB 和普通的网络迭代相比,多计算了一遍前向算子。 具体过程如下图所示:
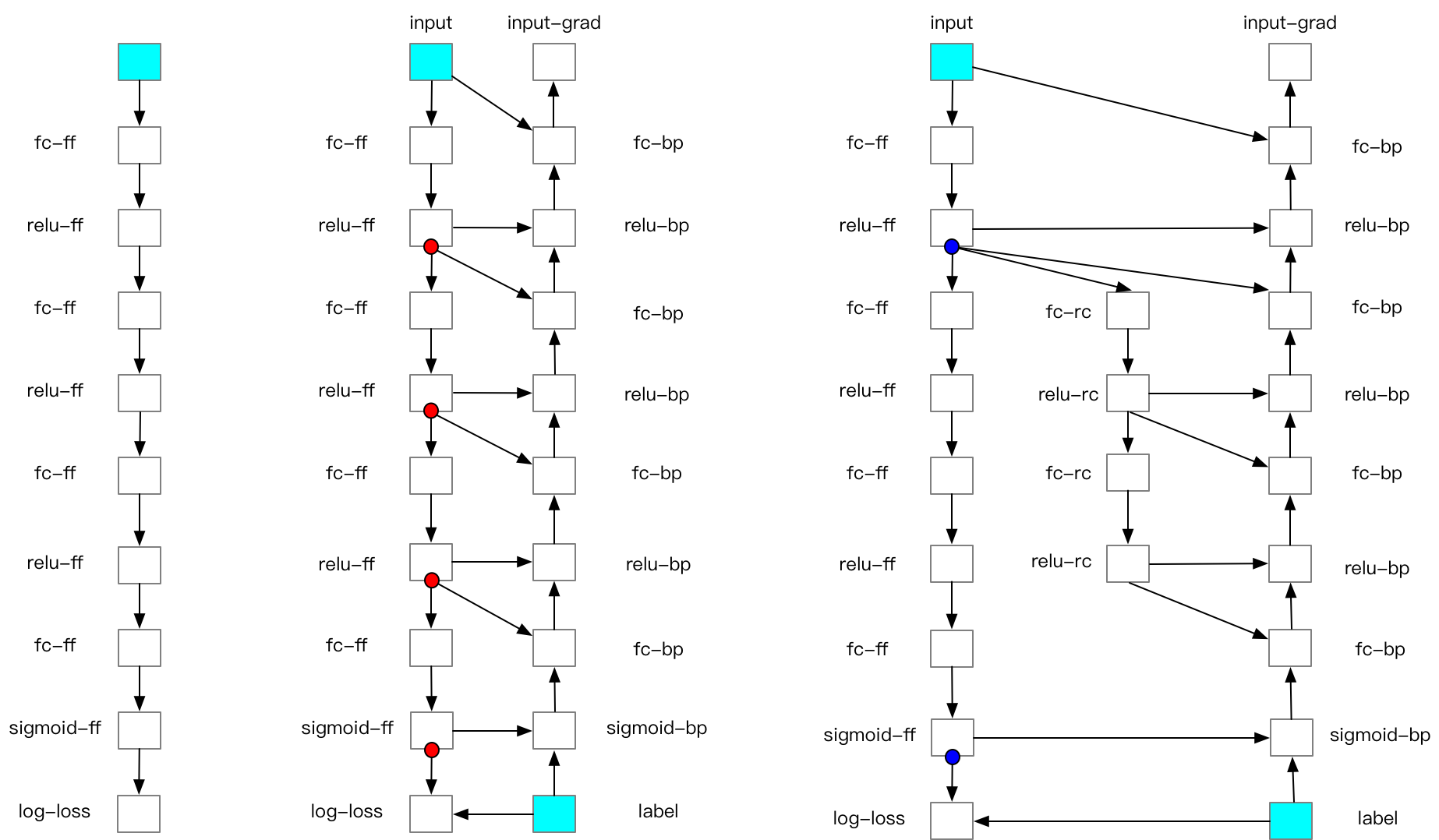
我们把切分网络的变量叫做checkpoints。 那么问题来了,如何选择checkpoints 呢?自从FRB方法提出以来,大量学者在研究这一关键问题。 我们知道深度学习网络通常是由一个个模块串联得到的,比如ResNet-50由16个block串联而成, Bert-Large由24个Encoder layers 串联而成,以两个子模块中间的变量作为切分点就是一个很好的选择。 对于非串联的网络(比如含有大量shortcut结构的网络),FRB也支持对其做切分, 只是可能多耗费一点内存(用于存储shortcut的Variable)。
5.1.2.2. Recompute-Offload¶
在上面的Recomputation 步骤中,同样作为Forward 中间结果的checkpoints 会驻留显存,方便在Backward 中重计算。 然而在checkpoint 的生命周期中,仍有一段较长的未被使用的,从极致节省显存的角度去看, 这也是对显存的一种浪费。 Recompute-Offload 原理大致可以分为两步:
Forward: 当checkpoint在前向中被生成后,将其卸载(Offload)到Host 内存中,让其所占据的显存可以被释放。
Backward:当checkpoint在反向中被重新调用之前,将其预取(Pre-fetch) 回显存中,完成之后的重计算。
注意:
因为checkpoint 在内存和显存间的拷贝较慢,该策略是通过进一步牺牲速度换取更大的batch size, 需要用户权衡训练吞吐和batch size 。
Recompute-Offload 支持多卡并行训练, 当多卡并行时开启Offload,训练中同一节点上所有GPU 上的checkpoints 都将卸载到Host 内存中,会存在以下风险:
PCIe 带宽瓶颈: 同一节点上的所有GPU 和Host 内存间共享一根PCIe 带宽,如同一节点上GPU 数量较多(单机八卡)容易因为PCIe 带宽限制让训练速度进一步减慢
Host 内存溢出: 当同一节点上GPU 数量较多,且每张GPU checkpoints size 较大时,需要注意卸载量是否超出Host 内存大小。
5.1.3. 效果¶
我们在BERT-Large模型上对Recompute 的效果进行了测试,Recompute 可以让batch size 扩大 10倍, Offload 可以在Recompute 的基础上再扩大1.43 倍。 batch size = #seq * seq_max_len 硬件: 单卡 V100 32GB
策略 |
amp |
amp + Recompute |
amp + Recompute + offload |
|---|---|---|---|
batch size |
18 * 512 |
180 * 512 |
258 * 512 |
speed |
23.94 sents/s |
17.82 sents/s |
15.47 sents/s |
5.1.4. 使用方法¶
为了使用Recompute策略,我们将dist_strategy.recompute设置为True
并设置我们事先定义好的checkpoints。 checkpoint 的选取可以参考论文 《Training Deep Nets with Sublinear Memory Cost》 。
示例中使用的ResNet50 模型的 checkpoint 不是固定的,不符合 Offload 的要求,固该功能暂无法开启。 当使用 Transformer 时,可以选取每一layer 的FC output 作为checkpoint, 这时各个layer 的checkpoints shapes 一致,可以使用Offload。
res2a.add.output.5.tmp_0 等是用户组网时定义的 variable name
checkpoint_idx = ["2a", "2b", "2c", "3a", "3b", "3c", "3d", "4a", "4b", "4c", "4d", "4e", "4f", "5a", "5b", "5c"]
checkpoints = ['res{}.add.output.5.tmp_0'.format(idx) for idx in checkpoint_idx]
strategy = fleet.DistributedStrategy()
strategy.recompute = True
strategy.amp = True
strategy.recompute_configs = {
"checkpoints": checkpoints,
"enable_offload": False,
"checkpoint_shape": []
}
上述例子的完整代码存放在:train_fleet_recompute.py下面。假设要运行2卡的任务,那么只需在命令行中执行:
fleetrun --gpus=0,1 train_fleet_recompute.py
您将看到显示如下日志信息:
----------- Configuration Arguments -----------
gpus: 0,1
heter_worker_num: None
heter_workers:
http_port: None
ips: 127.0.0.1
log_dir: log
...
------------------------------------------------
...
+=======================================================================================+
| Distributed Envs Value |
+---------------------------------------------------------------------------------------+
| PADDLE_CURRENT_ENDPOINT 127.0.0.1:17901 |
| PADDLE_TRAINERS_NUM 2 |
| PADDLE_TRAINER_ENDPOINTS 127.0.0.1:17901,127.0.0.1:18846 |
| FLAGS_selected_gpus 0 |
| PADDLE_TRAINER_ID 0 |
+=======================================================================================+
...
+==============================================================================+
| |
| DistributedStrategy Overview |
| |
+==============================================================================+
| amp=True <-> amp_configs |
+------------------------------------------------------------------------------+
| init_loss_scaling 32768.0 |
| incr_every_n_steps 1000 |
| decr_every_n_nan_or_inf 2 |
| incr_ratio 2.0 |
| decr_ratio 0.800000011920929 |
| use_dynamic_loss_scaling True |
+==============================================================================+
| recompute=True <-> recompute_configs |
+------------------------------------------------------------------------------+
| checkpoints res2a.add.output.5.tmp_0 |
| res2b.add.output.5.tmp_0 |
| res2c.add.output.5.tmp_0 |
| res3a.add.output.5.tmp_0 |
| res3b.add.output.5.tmp_0 |
| res3c.add.output.5.tmp_0 |
| res3d.add.output.5.tmp_0 |
| res4a.add.output.5.tmp_0 |
| res4b.add.output.5.tmp_0 |
| res4c.add.output.5.tmp_0 |
| res4d.add.output.5.tmp_0 |
| res4e.add.output.5.tmp_0 |
| res4f.add.output.5.tmp_0 |
| res5a.add.output.5.tmp_0 |
| res5b.add.output.5.tmp_0 |
| res5c.add.output.5.tmp_0 |
| enable_offload False |
+==============================================================================+
...
W0104 17:59:19.018365 43338 device_context.cc:342] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.2, Runtime API Version: 9.2
W0104 17:59:19.022523 43338 device_context.cc:352] device: 0, cuDNN Version: 7.4.
W0104 17:59:23.193490 43338 fuse_all_reduce_op_pass.cc:78] Find all_reduce operators: 161. To make the speed faster, some all_reduce ops are fused during training, after fusion, the number of all_reduce ops is 5.
[Epoch 0, batch 0] loss: 0.12432, acc1: 0.00000, acc5: 0.06250
[Epoch 0, batch 5] loss: 1.01921, acc1: 0.00000, acc5: 0.00000
...
完整2卡的日志信息也可在./log/目录下查看。了解更多fleetrun的用法可参考左侧文档fleetrun 启动分布式任务。