3. 优化低配网络的分布式GPU训练¶
在网络带宽较低的训练场景(如:
共有云上训练,联邦训练)中,梯度同步在低带宽网络下的延迟成为训练速度的主要瓶颈。
Fleet 实现了: Deep Gradient Compression 和 Local SGD
两种训练策略来针对性解决这一问题。
3.1. DGC 优化低配网络的分布式GPU训练¶
3.1.1. DGC 简介¶
大规模分布式训练需要较高的网络带宽以便进行梯度的聚合更新,这限制了多节点训练时的可扩展性同时也需要昂贵的高带宽设备。在低带宽云网络等环境下进行分布式训练会变得更加糟糕。
Deep Gradient Compression
发现:分布式SGD中有99.9%的梯度交换都是冗余的,可以使用深度梯度压缩选择重要梯度进行通信来减少通信量,降低对通信带宽的依赖。Fleet
实现了DGC的稀疏通信方式,可有效在低配网络下进行GPU分布式训练。Fleet
实现了 DGC 论文中的 预热训练 (warming up training),
动量修正 (Momentum Correction),
局部梯度修剪 (local gradient clipping),
动量因子掩藏 (Momentum factor masking) 等策略, 和
正则化项修正 (Weight Decay Correction)
避免稀疏梯度通信训练带来的最终模型精度损失。
下面将介绍 DGC 稀疏通信方式的适用场景及、基本原理,Fleet 中 DGC 的效果和使用方法。
3.1.1.1. 适用场景¶
DGC稀疏通信在低带宽通信瓶颈时会有较大的性能提升,但在单机多卡及RDMA网络通信并非瓶颈情况下,并不会带来性能上的提升。同时由于AllGather的通信量会随卡数的增多而增大,所以DGC的多机训练规模也不宜过大。故DGC适用于低配网络,同时节点规模不宜过大,如>128张卡。在云网络或高带宽网络设备昂贵时,DGC可有效降低训练成本。
3.1.2. Fleet 效果¶
模型:FasterRCNN
硬件: P40两机分布式,每台机器一卡,TCP网络测试。
取300-700步耗时/400step。
精度无损。
带宽 |
训练耗时-Momentum(step /s) |
训练耗时-DGCMomentum(step /s) |
比率 |
|---|---|---|---|
100G |
0.3725 |
0.375 |
0.993 |
10G |
0.55 |
0.375 |
1.467 |
1G |
2.45 |
0.375 |
6.533 |
3.1.3. DGC 原理¶
3.1.3.1. 梯度稀疏¶
DGC的基本思路是通过只传送重要梯度,即只发送大于给定阈值的梯度来减少通信带宽的使用。为避免信息的丢失,DGC会将剩余梯度在局部累加起来,最终这些梯度会累加大到足以传输。 换个角度,从理论依据上来看,局部梯度累加等同于随时间推移增加batch size,(DGC相当于每一个梯度有自己的batch size)。设定 \(F(w)\) 为需要优化的loss函数,则有着N个训练节点的同步分布式SGD更新公式如下
其中\(\chi\)是训练集,\(w\)是网络权值,\(f(x, w)\)是每个样本\(x \in \chi\)的loss,\(\eta\)是学习率,N是训练节点个数,\(\mathcal{B}_{k, t}\)代表第\(k\)个节点在第\(t\)个迭代时的minibatch,大小为b。 考虑权重的第i个值,在T次迭代后,可获得
等式2表明局部梯度累加可以被认为batch size从\(Nb\)增大为\(NbT\),其中T是\(w^{(i)}\)两次更新的稀疏通信间隔。
3.1.3.2. 预热调参¶
对于正常的训练,使用DGC一般需进行预热训练,否则可能会有精度损失。如下图是ResNet50模型Imagenet数据集的训练结果,未进行预热训练的DGC最终损失了约0.3%的精度。
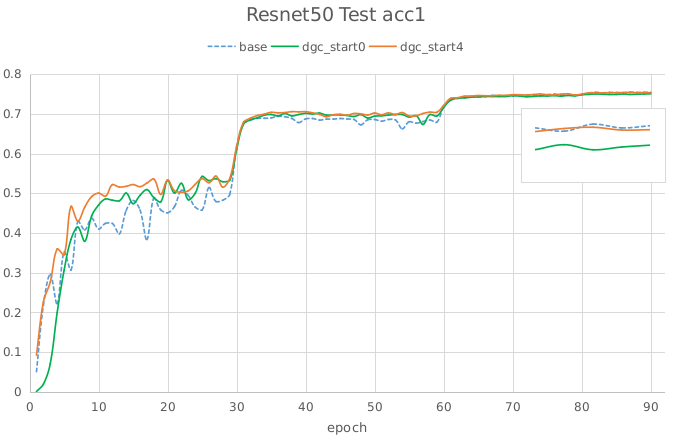
预热训练调参可参照论文的设置。论文中使用了 75%, 93.75%, 98.4375%, 99.6%, 99.9% 稀疏度逐渐提升的策略。由于paddle稀疏梯度聚合通信使用了AllGather,通信量会随卡数增加而增长,所以在卡数较多时不推荐较低稀疏度的预热训练。如75%稀疏度时每张卡会选择25%的梯度进行通信,卡数为32时通信量是正常dense通信的32*(1-0.75)=8倍,所以前几个epoch使用正常的dense通信为佳。可参照如下设置参数:
# 1. 以1252个step为一个epoch,前2个epochs使用正常dense通信,后3个epochs逐步提升稀疏度为99.9%
strategy.dgc_configs = {
"rampup_begin_step": 1252*2,
"rampup_step": 1252*3,
"sparsity": [0.984375, 0.996, 0.999]
}
# 2. 前面4个epochs都使用dense通信,之后默认0.999稀疏度运行
strategy.dgc_configs = {
"rampup_begin_step": 1252*4,
"rampup_step": 1,
"sparsity": [0.999]
}
对于Fine-tuning训练,现测试可无需预热训练,从第0个epoch直接使用DGC即可。
# 从第0步开始DGC稀疏通信
strategy.dgc_configs = {
"rampup_begin_step": 0,
"rampup_step": 1,
"sparsity": [0.999]
}
3.1.3.3. 局部梯度累加改进¶
正常情况,稀疏更新会严重影响收敛性。DGC中采用动量修正(Momentum Correction)和局部梯度裁减(Local Gradient Clipping)来解决这个问题。
3.1.3.3.1. 动量修正¶
有着N个节点分布式训练中vanilla momentum SGD公式,
其中\(m\)是动量因子,\(N\)是节点数,\(\nabla_{k, t}=\frac{1}{N b} \sum_{x \in \mathcal{B}_{k, t}} \nabla f\left(x, w_{t}\right)\)。 考虑第i个权重\(w^{(i)}\),在T次迭代后,权重更新公式如下,
如果直接应用动量SGD到稀疏梯度更新中,则有公式,
其中\(v_k\)是训练节点k上的局部梯度累加项,一旦\(v_k\)大于某一阈值,则会在第二项中压缩梯度进行动量更新,并使用sparse()函数获得mask清空大于阈值的梯度。 \(w^{(i)}\)在T次稀疏更新后的权重为,
相比传统动量SGD,方程6缺失了累积衰减因子\(\sum_{\tau=0}^{T-1} m^{\tau}\),会导致收敛精度的损失。如下图(a),正常梯度更新从A点到B点,但是方程6则从A点到C点。当稀疏度很高时,会显著降低模型性能,所以需要在方程5基础上对梯度进行修正。
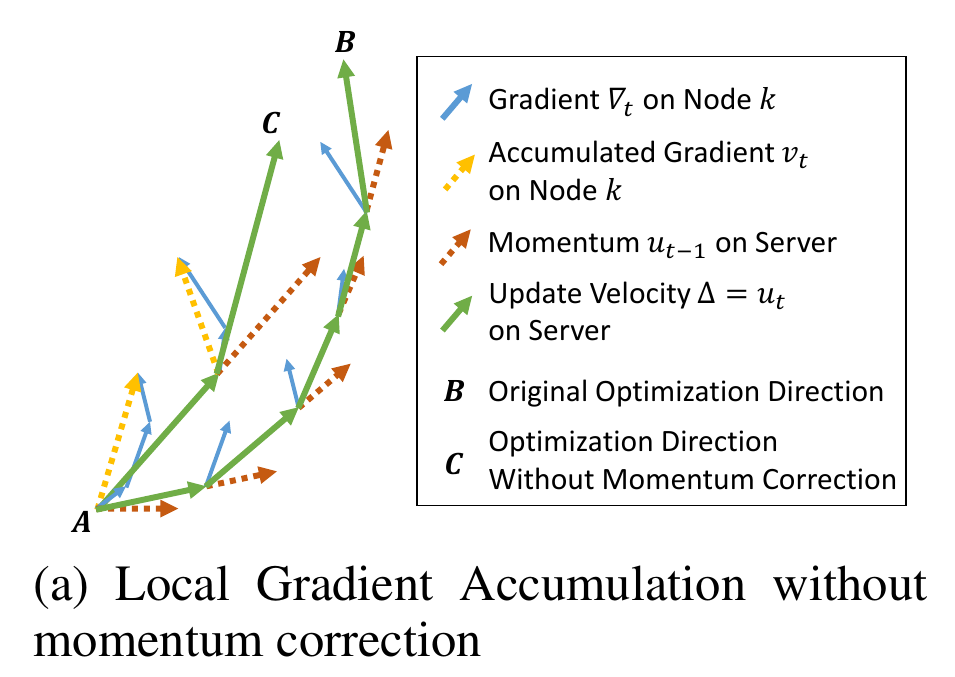
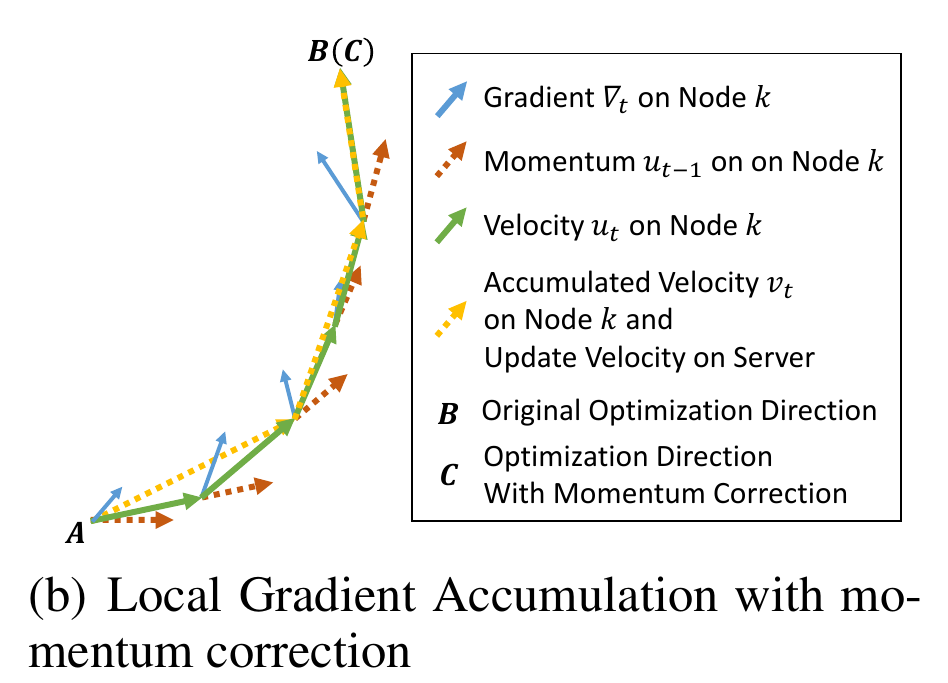
若将方程3中速度项\(u_t\)当作“梯度”,则方程3第二项可认为是在”梯度“\(u_t\)上应用传统SGD,前面已经证明了局部梯度累加在传统SGD上是有效的。因此,可以使用方程3局部累加速度项\(u_t\)而非累加真实的梯度\(\nabla_{k, t}\)来修正方程5,
修正后,如上图(b),方程可正常从A点到B点。除了传统动量方程修正,论文还给出了Nesterov动量SGD的修正方程。
3.1.3.3.2. 局部梯度修剪¶
梯度修剪是防止梯度爆炸的常用方法。这方法由Pascanu等人在2013年提出,当梯度的l2-norms和大于给定阈值时,就对梯度rescale。正常梯度修剪在梯度聚合后使用,而DGC因为每个节点独立的进行局部梯度累加,所以DGC在使用\(G_t\)累加前对其进行局部梯度修剪。阈值缩放为原来的\(N^{-1/2}\)
3.1.3.4. 克服迟滞效应¶
因为推迟了较小梯度更新权重的时间,所以会有权重陈旧性问题。稀疏度为99.9%时大部分参数需600到1000步更新一次。迟滞效应会减缓收敛并降低模型精度。DGC中采用动量因子掩藏和预热训练来解决这问题。
3.1.3.4.1. 动量因子掩藏¶
DGC中使用下面方程来掩藏动量因子减缓陈旧性问题。
此掩码可以停止延迟梯度产生的动量,防止陈旧梯度把权重引入错误的方向。
3.1.3.5. 正则化(Weight Decay)项修正¶
Paddle框架以Weight Decay的形式实现正则化。以L2Decay为例,公式(3)中传统momentum添加weight decay后公式为
其中\(\lambda\)为Weight Decay系数,\(G_{t}\)为添加L2Decay项之后的聚合梯度。由于在公式7中进行了局部动量修正,所以按照相同思路在局部梯度上运用修正的Weight Decay项。如下公式在局部梯度上添加局部Weight Decay项即可。
在模型实际训练中,通常会设置weight decay的系数\(\lambda=10^{-4}\),在卡数较多如4机32卡的情况下局部weight decay系数为\(\frac{\lambda}{N}=\frac{10^{-4}}{32}=3.125\*10^{-6}\),在数值精度上偏低,测试训练时会损失一定精度。为此还需对局部weight decay项进行数值修正。如下公式,
具体做法为对局部梯度乘以卡数求得\(\nabla_{k, t}^{'}\),此时\(\lambda\)项则无需除以卡数,聚合梯度求得\(G_{t}^{'}\)再对聚合梯度除以卡数得到\(G_{t}\)即可。
上述策略已经在框架中实现,用户无须设置。
3.1.4. DGC 快速开始¶
下文以单机八卡上训练ResNet50 为例子简单介绍 Fleet 中 DGC 的使用。 因为 8张 GPU 的通信都在同一节点内, 一般情况下梯度通信并不会成为训练的瓶颈, 这里只是以其为例子,介绍Fleet 中 DGC 参数的设置。
注意:
硬件环境要求: DGC目前只支持GPU多卡及分布式collective训练,需要有相应的cuda、cuDNN、nccl环境。
Paddle环境要求: DGC只支持GPU,所以需GPU版本的Paddle。
3.1.4.1. 添加依赖¶
import os
import fleetx as X
import paddle.fluid as fluid
import paddle.distributed.fleet.base.role_maker as role_maker
import time
import paddle.distributed.fleet as fleet
3.1.4.2. 定义分布式模式并初始化¶
通过X.parse_train_configs()接口,用户可以定义训练相关的参数,如:学习率、衰减率等。同时通过fleet.init()接口定义了分布式模型,下面代码中的is_collective=True表示采用集合通信的GPU分布式模式训练模型。
configs = X.parse_train_configs()
role = role_maker.PaddleCloudRoleMaker(is_collective=True)
fleet.init(role)
3.1.4.3. 加载模型及数据¶
用户可以通过X.applications接口加载我们预先定义好的模型,如:Resnet50、VGG16、BERT等。并使用定制化的data_loader加载模型,同时可以定义训练中使用的batch_size等参数。
model = X.applications.Resnet50()
batch_size = 32
loader = model.load_imagenet_from_file("/pathto/ImageNet/train.txt")
3.1.4.4. DGC 相关策略¶
这里假设:1252个step为一个epoch,前2个epochs使用正常dense通信,后3个epochs逐步提升稀疏度为99.9%
rampup_begin_step (int):DGC(含预热训练)开始的 steprampup_step (int):DGC中预热训练持续的 step. 如果sparsity 是 [0.75, 0.9375, 0.984375, 0.996, 0.999],rampup_step 设成 100时, 在 0~19 steps 时 sparsity=0.75,在 20~39 steps 时 sparsity=0.9375, 以此类推。sparsity (list[float]):稀疏度 threshold, (1 - current sparsity) % 的gradient 将会被 allreduce。
dist_strategy = fleet.DistributedStrategy()
dist_strategy.lars = True
dist_strategy.dgc_configs = {
"rampup_begin_step": 1252*2,
"rampup_step": 1252*3,
"sparsity": [0.984375, 0.996, 0.999]
}
optimizer = fluid.optimizer.Momentum(learning_rate=0.01, momentum=0.9)
optimizer = fleet.distributed_optimizer(optimizer, dist_strategy)
optimizer.minimize(model.loss)
3.1.4.5. 开始训练¶
这一部分和Fleet 中其他任务基本相同:
place = fluid.CUDAPlace(int(os.environ.get('FLAGS_selected_gpus', 0)))
exe = fluid.Executor(place)
exe.run(fluid.default_startup_program())
for i, data in enumerate(data_loader()):
start_time = time.time()
cost_val = exe.run(model.main_prog,
feed=data,
fetch_list=[model.loss.name])
end_time = time.time()
print(
"worker_index: %d, step%d cost = %f, speed: %f"
% (fleet.worker_index(), i, cost_val[0], batch_size / (end_time - start_time)))
3.1.4.6. 运行训练脚本¶
一行启动单机多卡分布式训练:
fleetrun --gpus 0,1,2,3,4,5,6,7 --log_dir log ./resnet50_dgc.py
# reader shuffle seed 0
# trainerid, trainer_count 0 8
# read images from 0, length: 160146, lines length: 160146, total: 1281168
# worker_index: 0, step0 cost = 7.151402, speed: 37.698432
# worker_index: 0, step1 cost = 7.112389, speed: 101.518513
# worker_index: 0, step2 cost = 7.004275, speed: 111.062341
# worker_index: 0, step3 cost = 7.039385, speed: 62.173126
# worker_index: 0, step4 cost = 6.985911, speed: 104.058060
# ......
3.2. 使用Local SGD 优化低带宽下分布式训练¶
3.2.1. Local SGD 简介¶
在使用 distributed SGD 进行数据并行的分布式训练时,常会遇到以下两个问题:
分布式训练的吞吐会受到集群中随机慢节点(straggling node)和通信延迟的影响。
数据并行分布式增大了训练实际的batch size,过大的batch size 会影响最终的训练精度。
Local SGD
通过延长节点间同步的间隔(局部异步训练)来减轻慢节点的影响和减少通信频率,以此提升训练的吞吐速度;另一方面,为了减小相对于本地训练(小batch
size)的精度损失,[1] 和 [2]
分别提出了:post-Local SGD 和
自适应步长 (Adaptive Communication) Local SGD
策略,来减少参数同步频率降低带来的精度损失。 同步SGD 和 Local
SGD 在通信同步上的差异如下图所示。
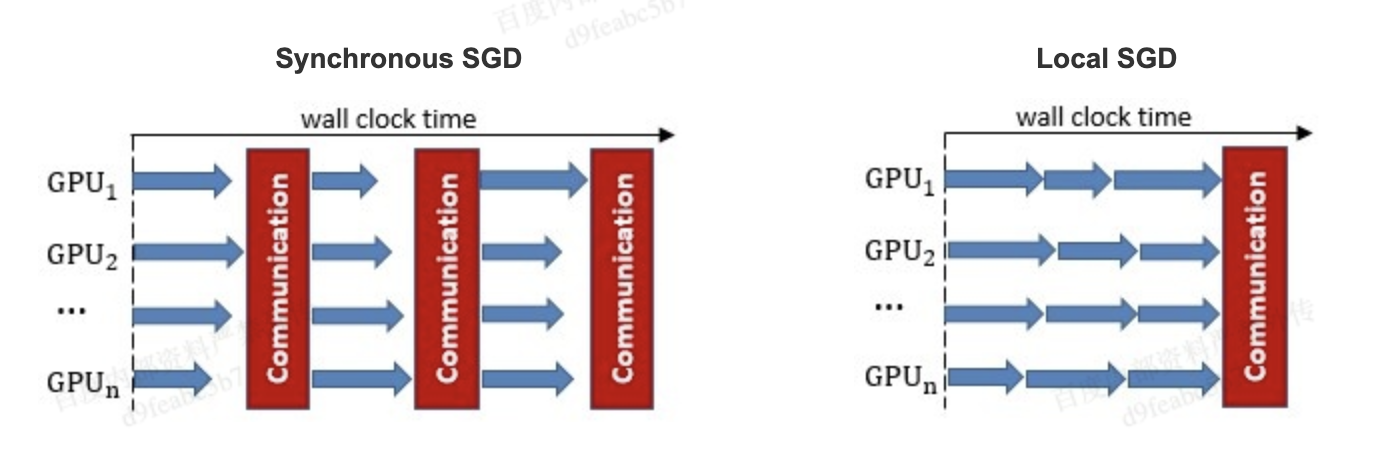
在Local SGD 训练中,集群中的每个 worker 各自会独立的进行 H 个连续的 SGD 更新, 然后集群中的所有 worker 会进行通信,同步(averaging)所有 workers 上的参数。一个双 workers,同步间隙为3 步长(iterations) 的Local SGD过程如下图所示。黄绿两条路径表示两个 workers 各自的 Local SGD 更新过程,中间的蓝色路径表示同步后的模型所在的位置。
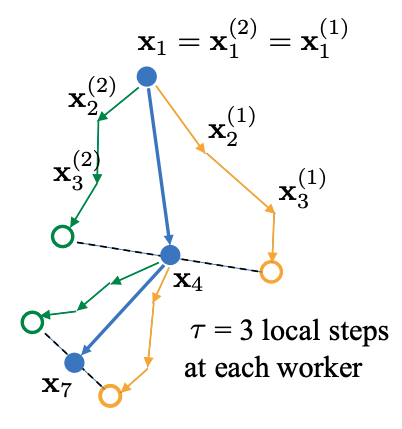
Local SGD中的一个关键问题是如何确定参数同步的间隔(频率),以到达训练吞吐和训练精度间更好的平衡:
增大参数同步的间隔可以减少 workers 间通信延迟的影响提高训练吞吐.
但增大同步间隔可能会造成最终训练精度的损失。 [1]
以下两个策略从不同角度试图达到更好的平衡:
post Local SGD 将训练过程分成两个阶段:第一阶段 wokers 间同步的间隔为 1 个步长,即同步SGD,来保证最终训练精度;在第二阶段增大同步间隔到固定常数 H,来提升训练吞吐。
Adaptive Communication Local SGD 通过动态的调整参数同步的间隔来尝试达到训练吞吐和精度间的更好的平衡。在训练初始或者上一段参数同步完成后,根据如下公式计算一下次参数同步的间隔(iteration)。详细的公式推导和参数定义请参考原论文。
Fleet 中实现了 post Local SGD 和
Adaptive Communication Local SGD 两种策略。 中下文将给出 Fleet中
Local SGD 的实践效果,并通过一个简单例子介绍如何在Fleet 中使用 Local
SGD。
3.2.2. Fleet 效果¶
试验设置
model |
dataset |
local batch size |
cluster |
dtype |
warming up |
learning rate decay |
|---|---|---|---|---|---|---|
resnet50 |
Imagenet |
128 |
4 x 8 x V100 |
FP32 |
30 |
polynomial |
试验结果
local step |
qps |
acc1 |
acc5 |
|---|---|---|---|
1 |
8270.91 |
0.7579 |
0.9266 |
2 |
8715.67 |
0.7533 |
0.9265 |
4 |
8762.66 |
0.7551 |
0.9260 |
8 |
9184.62 |
0.7511 |
0.9239 |
16 |
9431.46 |
0.7429 |
0.9206 |
ADACOMM |
8945.74 |
0.7555 |
0.9270 |
可以看到在 post Local SGD (固定同步间隔)情况下,更新间隔越长训练的吞吐越高,但是模型的最终进度也会损失越大。 当使用 ADAPTIVE COMMUNICATION 策略后,训练在吞吐和精度间达到了一个更好的平衡。
3.2.3. Local SGD 快速开始¶
下文将以在单机8卡中训练 ResNet50 为例子简单介绍 Fleet 中 Local SGD 的用法。 需要注意的是 单机八卡的通信都在同一节点内, 一般情况下参数同步并不会成为训练的瓶颈, 这里只是以其为例子,介绍Fleet 中 Local SGD 参数的设置。
3.2.3.1. 添加依赖¶
import os
import fleetx as X
import paddle.fluid as fluid
import paddle.distributed.fleet.base.role_maker as role_maker
import time
import paddle.distributed.fleet as fleet
3.2.3.2. 定义分布式模式并初始化¶
通过X.parse_train_configs()接口,用户可以定义训练相关的参数,如:学习率、衰减率等。同时通过fleet.init()接口定义了分布式模型,下面代码中的is_collective=True表示采用集合通信的GPU分布式模式训练模型。
configs = X.parse_train_configs()
role = role_maker.PaddleCloudRoleMaker(is_collective=True)
fleet.init(role)
3.2.3.3. 加载模型及数据¶
用户可以通过X.applications接口加载我们预先定义好的模型,如:Resnet50、VGG16、BERT等。并使用定制化的data_loader加载模型,同时可以定义训练中使用的batch_size等参数。
model = X.applications.Resnet50()
batch_size = 32
loader = model.load_imagenet_from_file("/pathto/ImageNet/train.txt")
3.2.3.4. 定义Local SGD 相关策略¶
用户首先需要定义paddle SGD 对象,并在SGD 对象中设置学习率参数。目前local SGD和自适应步长 local SGD都仅支持SGD和Momentum两种优化器。
在post Local SGD 中,有两个用户设置参数
begin_step和k_steps,局部更新和参数同步都由框架自动完成。begin_step 指定从第几个step之后进行local SGD算法,取值为大于0的整数;k_step 指定训练过程中的全局参数更新间隔,取值为大于0的整数。
dist_strategy = fleet.DistributedStrategy()
dist_strategy.localsgd = True
dist_strategy.localsgd_configs = {
"k_steps": 1,
"begin_step": 1,
}
optimizer = fluid.fluid.optimizer.SGD(learning_rate=0.01)
optimizer = fleet.distributed_optimizer(optimizer, dist_strategy)
optimizer.minimize(model.loss)
在 自适应步长 local SGD 中,有两个用户设置参数
begin_step和init_k_steps。begin_step 指定从第几个step之后进行自适应local SGD算法,取值为大于0的整数;用户需要设置init_k_steps作为第一次参数同步的间隔,之后的同步间隔将由上文中的公式动态确定,在学习率较大时,参数变化大,减小step,多进行通信从而保证快速收敛;在学习率较小时,参数变化小,增大step,减少通信次数,从而提升训练速度。 需要注意的是自适应步长策略中,系统会默认限制最大的同步间隔为 16 step,当公式计算出的间隔大于16 时,按16 steps 进行参数同步。
dist_strategy = fleet.DistributedStrategy()
dist_strategy.adaptive_localsgd = True
dist_strategy.adaptive_localsgd_configs = {
"init_k_steps": 1,
"begin_step": 1,
}
optimizer = fluid.fluid.optimizer.SGD(learning_rate=0.01)
optimizer = fleet.distributed_optimizer(optimizer, dist_strategy)
optimizer.minimize(model.loss)
3.2.3.5. 开始训练¶
这一部分和Fleet 中其他任务基本相同:
place = fluid.CUDAPlace(int(os.environ.get('FLAGS_selected_gpus', 0)))
exe = fluid.Executor(place)
exe.run(fluid.default_startup_program())
for i, data in enumerate(data_loader()):
start_time = time.time()
cost_val = exe.run(model.main_prog,
feed=data,
fetch_list=[model.loss.name])
end_time = time.time()
print(
"worker_index: %d, step%d cost = %f, speed: %f"
% (fleet.worker_index(), i, cost_val[0], batch_size / (end_time - start_time)))
3.2.3.6. 运行训练脚本¶
一行启动单机多卡分布式训练:
fleetrun --gpus 0,1,2,3,4,5,6,7 --log_dir log resnet50_localsgd.py
# reader shuffle seed 0
# trainerid, trainer_count 0 8
# read images from 0, length: 160146, lines length: 160146, total: 1281168
# worker_index: 0, step0 cost = 7.151402, speed: 37.698432
# worker_index: 0, step1 cost = 7.112389, speed: 101.518513
# worker_index: 0, step2 cost = 7.004275, speed: 111.062341
# worker_index: 0, step3 cost = 7.039385, speed: 62.173126
# worker_index: 0, step4 cost = 6.985911, speed: 104.058060
# ......